If you've spent any time around AI tools — especially the API side — you've probably bumped into terms like temperature, top-p, tokens, context window, RLHF, and a dozen others. Most documentation explains them assuming you already half-know what they mean. This glossary is the version I wish I'd had when I started: plain-English definitions, why each term matters, and when you'd actually touch it.
It's organized into five buckets — pick the section you need or read it end to end as a primer.
- 1. Tokens & context — what AI actually reads and writes
- 2. The sampling dials — temperature, top-p, top-k, and friends
- 3. How models think — architecture and inference
- 4. Training & alignment — how a model becomes useful
- 5. Putting models to work — RAG, agents, tools, streaming
1. Tokens & context
Before any settings, you need the vocabulary for what the model is actually consuming and producing.
Token
The basic unit a language model reads and writes. A token is usually a chunk of a few characters — sometimes a whole short word ("cat"), sometimes a fragment ("ing", "tion"), sometimes a single character or even a byte. As a rough rule for English, 1 token ≈ 4 characters ≈ ¾ of a word, so 1,000 tokens is about 750 words. Pricing is almost always charged per token (input and output separately).
Tokenizer
The function that turns text into tokens before the model sees it. Different model families use different tokenizers, which is why the same paragraph can cost slightly different token counts on different platforms.
Context window (a.k.a. context length)
The maximum number of tokens the model can hold "in mind" at once — including your prompt, any system instructions, prior conversation, and the response it's generating. Modern frontier models offer 200K–1M token windows; older or cheaper models offer 8K–32K. If you exceed it, the oldest content gets dropped or your call fails.
Input tokens vs output tokens
Input tokens are what you send (prompt, system message, history, attached docs). Output tokens are what the model generates back. Output tokens are usually 3–5× more expensive than input tokens because generating is harder than reading.
Max tokens (max_output_tokens)
A per-request cap on how many tokens the model is allowed to generate before stopping. Set it to control cost and latency. Many APIs default to a few thousand; raise it for long outputs, lower it to keep responses short.
2. The sampling dials
When a model picks the next token, it actually has a probability distribution over all possible next tokens. The sampling dials shape how that distribution becomes a single choice. These are the levers most people touch via API.
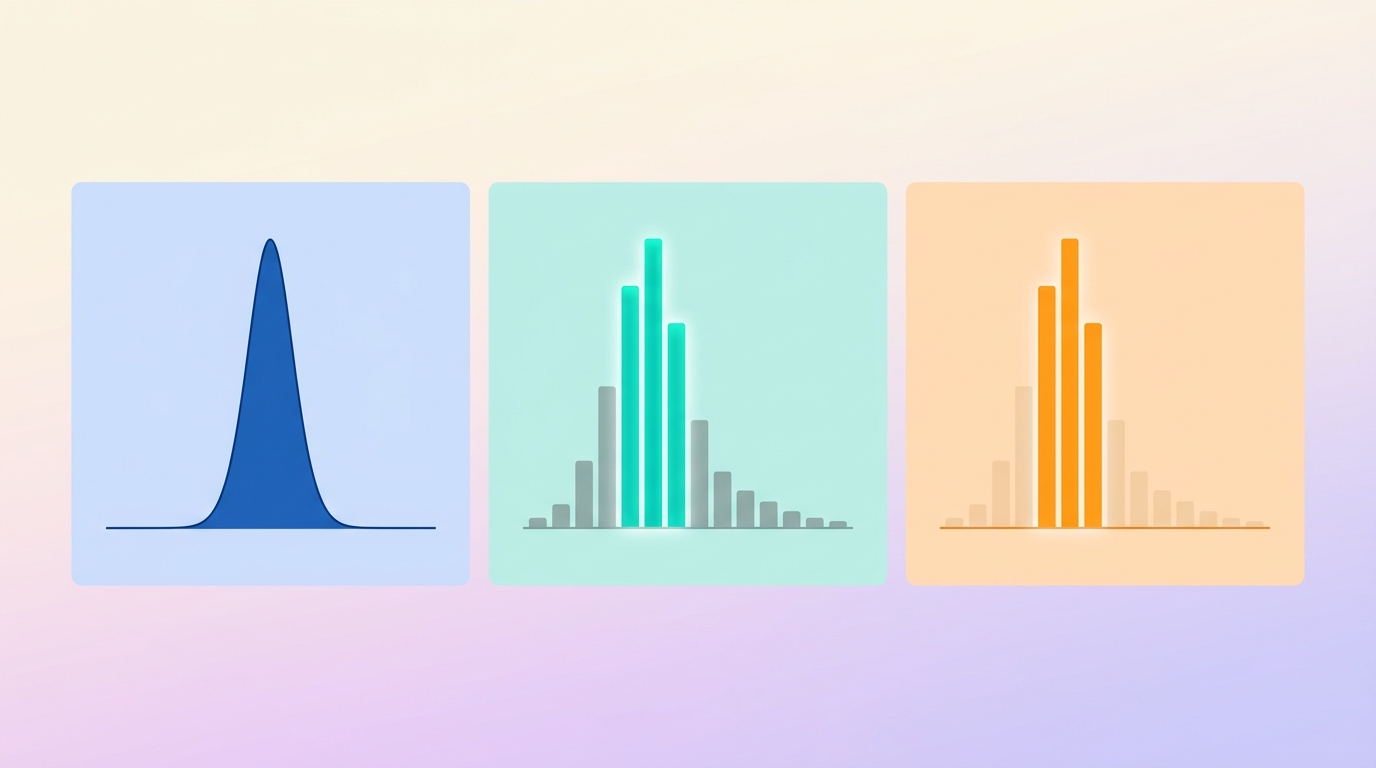
Temperature
Controls overall randomness. Low temperature (0–0.3) makes the model pick the most likely next token almost every time — deterministic, repetitive, "safe." High temperature (1.0+) flattens the probability distribution, making less likely tokens viable — more creative, more surprising, more error-prone. A good starting default for most chat use cases is 0.7. Drop to 0.0–0.2 for code, math, or factual extraction. Push to 1.0+ for creative writing or brainstorming.
Top-P (nucleus sampling)
Instead of considering all tokens, top-p says: "only consider the smallest set of tokens whose cumulative probability is at least P." So at top-p = 0.9, the model samples from the tokens that together cover 90% of the probability mass — ignoring the long tail. It's a smarter, dynamic alternative to top-k. Common default: 0.9 or 1.0 (off).
Top-K
Only consider the K most likely next tokens, then sample among those. Top-k = 1 is greedy decoding (always pick the single most likely token); top-k = 40 keeps the top 40 candidates. Modern APIs (OpenAI, Anthropic) often don't expose top-k directly because top-p tends to behave better, but it's standard on open-source models.
Frequency penalty
Penalizes tokens that have already been generated in the response so far, in proportion to how often they've appeared. Useful for reducing literal repetition. Range typically -2.0 to +2.0; default 0.
Presence penalty
Like frequency penalty, but binary: penalizes tokens that have appeared at all, regardless of count. Pushes the model toward introducing new topics or words. Same range, same default.
Stop sequences
Strings that force the model to halt generation when it produces them. Useful for structured output ("stop when you generate ###") or to keep responses inside a specific format.
Seed
An integer that pins the random number generator. Same prompt + same seed + same model version usually produces the same output, which is critical for reproducibility, evaluations, and debugging. Note: most providers describe this as "best-effort" — perfect determinism isn't guaranteed across infrastructure.
Quick comparison: temperature vs top-p vs top-k
The three sampling dials side-by-side
| Dial | What it does | Typical range | Push it higher | Push it lower |
|---|---|---|---|---|
| Temperature | Sharpens or flattens the whole probability curve | 0.0 – 2.0 (default ~0.7) | More creative, more random | More deterministic, more repetitive |
| Top-P | Keeps only the tokens covering P% of probability mass | 0.0 – 1.0 (default 0.9 – 1.0) | More variety in word choice | Tighter, safer outputs |
| Top-K | Keeps only the K most likely tokens | 1 – ∞ (often off in modern APIs) | More variety | Tighter; K=1 = greedy |
Common pitfall: tweaking all three at once. Pick one — usually temperature for creativity control, or top-p for diversity tuning — and leave the others at defaults. Stacking penalties on top of low temperature is where most "weird output" reports come from.
3. How models think
You don't need to be an ML engineer to use AI tools, but a few architecture terms come up constantly in product comparisons.
Parameters
The numbers inside the model that get tuned during training. A "70B model" has 70 billion of them. Bigger generally means smarter and more expensive, but the relationship has gotten less linear as architectures have improved — a well-trained smaller model can outperform a larger but older one.
Embedding
A vector (a list of numbers) that represents the meaning of a piece of text in high-dimensional space. Texts with similar meanings end up close together. Embeddings power semantic search, RAG, deduplication, classification, and recommendation. Different from a chat model — embedding models are smaller and specialized.
Attention
The mechanism that lets a model decide, when generating each new token, which previous tokens to "look at" most. It's the core innovation of transformers. You'll rarely touch it directly, but it's why context windows matter so much.
Transformer
The neural network architecture behind essentially every modern large language model since 2017. When someone says "an LLM," they almost always mean a transformer.
Mixture of Experts (MoE)
An architecture where the model is split into many "expert" subnetworks and only a fraction of them activate for each token. This means a model can have, say, 400B total parameters but only use 30B per token — getting big-model knowledge at small-model speed. Several frontier models use MoE under the hood.
Reasoning model
A model trained to spend extra compute "thinking" — generating internal reasoning steps — before producing its final answer. This dramatically improves performance on math, coding, and complex reasoning tasks but increases latency and token cost. Reasoning models are the dominant frontier-tier category in 2026.
Chain-of-thought (CoT)
Either a prompting technique ("think step by step") or a built-in behavior of reasoning models, where the model generates intermediate reasoning before its final answer. The reasoning steps are sometimes hidden from the user; with reasoning models you usually pay for them as output tokens regardless.
Quantization
Reducing the numerical precision of a model's parameters (e.g., from 16-bit floats to 4-bit integers) to shrink it and speed it up, usually with a small quality cost. Big in the open-source world; less visible when using closed-API models.
4. Training & alignment
How a giant pile of text becomes a model that politely answers your questions.
Pretraining
The first and most expensive stage of training, where the model learns general language and world knowledge by predicting the next token across enormous amounts of text. This is where most of the "intelligence" comes from.
Fine-tuning
A second training stage that adapts a pretrained model to a narrower task or style, using a much smaller dataset. Used for domain specialization (medical, legal, coding) or to align tone and behavior to a specific brand.
RLHF (Reinforcement Learning from Human Feedback)
The alignment technique that turned raw language models into useful assistants. Humans rate model outputs; a reward model is trained on those ratings; then the language model is fine-tuned with reinforcement learning to produce outputs the reward model prefers. RLHF is what makes ChatGPT and Claude refuse harmful requests, follow instructions politely, and stay on topic. RLAIF (with AI feedback) is a related technique now used at scale.
System prompt
The top-level instruction that sets the model's role, tone, constraints, and persona for an entire conversation. Treated with higher priority than user messages by most providers. This is where you tell the model what it is, before any specific task.
Hallucination
When the model produces a confident-sounding answer that's factually wrong or fabricated. Caused by a mix of training data gaps, the model's tendency to generate plausible-sounding text rather than verify, and over-confident phrasing. Mitigations: lower temperature, RAG (give it real sources), explicit "say I don't know" instructions, and verifying anything important.
Prompt engineering
The practice of writing prompts that reliably produce the output you want. Includes things like role-setting ("you are a..."), few-shot examples, chain-of-thought triggers, and structured output instructions. As models have gotten better at following instructions, prompt engineering has shifted from arcane tricks to clear writing.
5. Putting models to work
The terms you'll hear in product and engineering discussions, not training.
Inference
The act of running a trained model — i.e., generating output for a given input. Distinct from training. Inference cost is what API pricing is based on, and inference latency is what users feel.
RAG (Retrieval-Augmented Generation)
Before answering, fetch relevant documents from a separate knowledge base (usually via embedding similarity search) and stuff them into the prompt as context. RAG lets a small or generic model answer accurately about your private docs, current events, or anything outside its training data. The dominant pattern for "AI that knows about my stuff."
Tool use / function calling
Letting the model invoke external functions or APIs as part of its response — e.g., "look up the weather," "query a database," "send an email." The model emits a structured request, your code executes it, you feed the result back. This is what turns an LLM into something that can act, not just talk.
Agent
A loop in which a model uses tools and makes its own decisions over multiple steps to complete a goal — for example, browsing the web, editing files, or running a multi-step workflow. Modern agents are essentially "reasoning model + tools + iteration loop." A blurry term that means everything from a customer-support bot to an autonomous coding assistant.
Multimodal
A model that handles more than just text — most commonly images and text together (vision), increasingly audio and video too. "Multimodal" usually refers to a single model that natively understands multiple modalities, not a pipeline of separate ones.
Vision (or VLM — Vision-Language Model)
A specific case of multimodal: the model can take images as input alongside text. Used for OCR, diagram understanding, screenshot debugging, document analysis, and anything where "show, don't tell" matters.
Streaming
The model sends its response token by token as it generates, rather than waiting for the whole answer to complete. Critical for chat UX — users see the response unfold instead of staring at a spinner. Implemented as server-sent events on most APIs.
Time to first token (TTFT)
How long it takes from sending a request to receiving the first token of the response. The latency the user actually feels. Reasoning models have higher TTFT because they think before speaking; non-reasoning models stream the first token in fractions of a second.
Tokens per second
Throughput once generation starts. A modern fast model might produce 80–200+ tokens per second; reasoning models often run slower because they generate (and pay for) hidden reasoning tokens.
The shortest cheat-sheet possible
If you remember nothing else:
- Token = ¾ of a word. Pricing is per token.
- Context window = how much text the model can see at once.
- Temperature = creativity dial. Low for facts/code, high for ideas.
- Top-P = a smarter, modern alternative to top-k. Leave at default unless you have a reason.
- System prompt = the persona and rules for the whole conversation.
- RAG = how you make a model knowledgeable about your private stuff.
- Reasoning model = slower, more expensive, much smarter on hard problems.
- Hallucination = a confident wrong answer. Always verify.
That's most of what you'll meet day to day. The rest of this glossary is here for when one of these terms surfaces in a doc, a tweet, or a model card and you need a quick anchor.